

December 21, 2022
UnFAIR: The Limitations of FAIR’s Approach to Data

Katerina Gill
14 min read | Cyber Risk Quantification
December 21, 2022
This is blog 1 of 3 in our FAIR model series.
Legos were a significant part of my childhood. They gave me countless hours of entertainment, but beyond that – they gave me some of my first exposure to understanding how building a model works. Before building any lego design, you have to collect the necessary pieces. Often this means sorting through a pile of legos to find these pieces and then organizing them by shape, color and function. Compiling and organizing pieces is important because the last thing you want is to run out of a specific piece and destroy your project.
Much like building a lego design, you need the right pieces, aka data, to perform cyber risk quantification (CRQ). Without the right input data, your risk model does not produce actionable and defensible outputs that can be used to make informed risk management decisions.
There are a lot of CRQ methodologies out there, but one that has long been recognized in the industry is FAIR (Factor Analysis of Information Risk). Using a top-down approach, an analyst would use FAIR to analyze risk scenarios in your environment one at a time to determine the probable loss exposure to your organization. Connecting these risk scenarios to the FAIR model requires collecting large volumes of data and input from scenario-related experts or consultants. You can learn more about FAIR’s methodology and how it works here.
The FAIR methodology does not have a data collection process or influence data quality. This leads to challenges around implementing FAIR in practice. Collecting high-quality and defensible data required to implement FAIR can be difficult, if not impossible, for teams to accomplish. This is because many of the required data inputs are:
Operationalizing FAIR involves a lengthy manual process of scoping risk scenarios and repeatedly pulling together data from scenario-related experts around the organization or third-party consultants or industry metrics. Aside from needing a deep understanding of FAIR’s ontology, you’ll find yourself conducting lengthy discussions, posing questions and manually inputting your findings into an excel spreadsheet or a tool that guides you through the process of calculating cyber risk.
FAIR’s risk assessment is performed in four steps, each outlined in the diagram below. The first four steps involve manual data collection, while the last step analyzes the collected data using a Monte Carlo simulation to quantify risk.
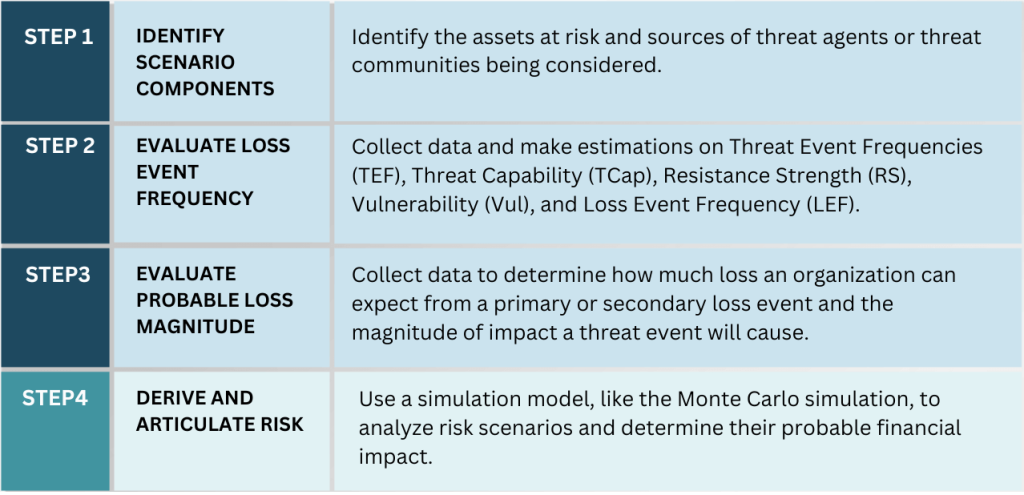
Step 1:
The type of data inputs you need for FAIR is highly influenced by the risk scenario being analyzed. To operationalize FAIR, you have to identify the assets of business value within your organization and determine threat actors, or probable risk scenarios, that could pose harm to the assets. Once you have clearly defined a scenario, the next step is to collect data about this scenario from experts in the organization or external sources.
Steps 2 and 3:
You can use FAIR’s risk equation model, shown in the flowchart below, to determine how loss might unfold for the possible risk scenario at hand. There are two main components that equate to cyber risk under FAIR: estimated frequency and magnitude of loss events.
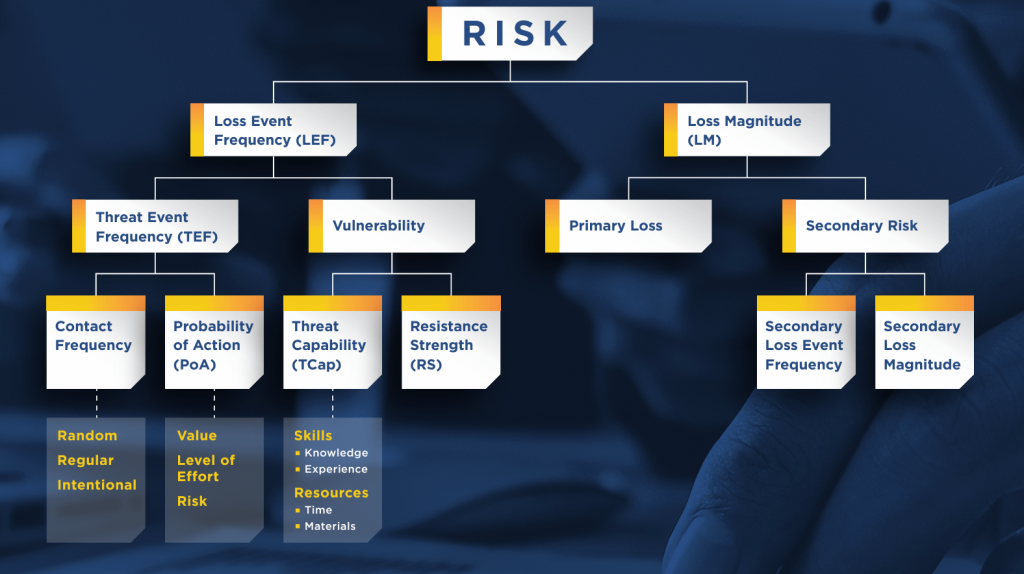
As you move down the flowchart and assess each risk factor, the risk scenario becomes more well-constructed and thought out, helping guide your data collection process. For example, a probable risk scenario could be one where malicious actors get access to your organization’s sensitive data by sending phishing emails to employees. Knowing this, you can collect data on how many devices are operating in your network, what vulnerabilities are on those devices that could potentially be exploited by the threat agent, the number of emails received by employees daily, how often a threat scenario of this nature might occur, and so on.
Step 4:
The last step involves analyzing the collected data using a Monte Carlo simulation to quantify risk.
If you think these four steps are time-consuming, you are probably not alone. Imagine having to perform this activity for every scoped risk scenario in your organization. Even if a clear risk scenario is defined, you might not know where the data exists, the type of data to source and how to make sense of the data you collected. The amount of time the data collection process takes is one of the major reasons why many organizations find FAIR impractical to scale.
The input data in your CRQ model should be objective, conclusive, and updated in real time to reflect the actual state of your network’s software and systems. It should also be comprehensive of your entire attack surface and reflect the business context of each asset.
Instead of utilizing data from your deployed cybersecurity, IT and business tools, a FAIR implementation typically involves a group of people defining a set of considered risk scenarios, collecting information based on these risks, and then assessing their estimated loss. The great deal of human intervention involved in this process means that FAIR tends to rely on subjective input data that is inevitably influenced by human opinion.
The data collection process can also be limiting. If data is sparse, nonexistent, or can’t be quantified, users are left to make assumptions, leading to data inputs that are open-ended and not defendable. For example, when users try to collect information for FAIR’s risk factors that are challenging to measure, such as secondary and primary loss, they might come up with answers that are inaccurate and highly biased. As a result, FAIR tends to yield vague outputs. These results leave many to question the accuracy of the data they collected and the credibility of the results.
An organization’s cyber risk is evolving daily, with new threats emerging faster than ever. Continuously monitoring your attack surface is the only way to truly understand what risks your organization is facing at all times.
One of the biggest drawbacks to FAIR is that — by itself — the methodology does not enable automation. While there are vendors that have attempted to automate much of the data collection process, those using the FAIR model without an enabling data platform find that it does not provide an accurate view of their cyber risk landscape. For one, FAIR utilizes data inputs that quickly become obsolete instead of data that is automatically and continuously pulled from your network. Moreover, maintaining the model in real-time is nearly impossible – risk scenarios need to be constantly re-analyzed and data needs to be collected as new threats emerge.
Without automation, it’s also challenging to spot pressing threats like Log4j within your network and reflect them in your risk analysis in real-time. Users would have to go through an extensive exercise to figure out the number of assets affected by a critical vulnerability and the impact it can have on their organization. As a result, users of FAIR are often left collecting inaccurate or outdated information that does not reflect the truth about their cyber risk.
Balbix was designed to enable cyber risk quantification to happen faster, more effectively, and more accurately. When it comes to data, we make sure that the data collection process is seamless and reflects your true risk landscape, allowing for a more accurate interpretation of your organization’s cyber risk.

While many other CRQ vendors align to the FAIR model, Balbix takes an entirely different approach to cyber risk quantification, particularly when it comes to data.
Balbix uses AI and automation to consolidate all of your risk information into a single unified model by ingesting asset-level data from your existing IT and security tools and threat data from external threat intelligence feeds. With Balbix, you can accurately inventory your cloud and on-premise assets, conduct risk-based vulnerability management, and quantify your cyber risk in monetary terms. The result is a faster and more seamless data collection process that doesn’t require time-consuming and resource-intensive risk assessments or repeatedly pulling data from members of your organization and third-party consultants.
Aside from allowing users to manually tune the breach risk model to their specific business requirements if needed, Balbix’s data collection and analysis process is completely automated and free of human intervention. This ensures that the data ingested into the model is objective, and concrete and overrides any biases and uncertainties as a result of human input. Automated data collected also reduces errors and enables Balbix to construct a fact-based CRQ model that produces outputs that can easily be traced to your underlying security issues.
Balbix connects to your existing security and IT tools and other data sources to unify and correlate asset and vulnerability data to build a near real-time asset-level cyber risk model. Using real data paints a comprehensive picture of your risk posture. It ensures that your risk calculation is accurate and accounts for threats across your entire network as soon as they emerge.
Learn more about the Balbix CRQ model and methodology and the benefits it brings to your cyber security program by scheduling a 30-minute demo with Balbix.