A Large Language Model (LLM) is an advanced form of artificial intelligence designed to understand, generate, and manipulate human language on a large scale. LLMs are trained on vast amounts of textual data, enabling them to produce coherent and contextually relevant responses to various prompts.
In summary, LLMs are AI systems that can read, comprehend, and generate text like humans, making interactions with technology more natural and intuitive.
This article will explain how they work, how they’re trained, what they’re used for, their upsides and downsides, and how they’re used in cybersecurity.
How Do LLMs Work?
LLMs operate through sophisticated machine learning techniques, using massive computational resources.
Imagine it like this: if learning new things for humans means reading books or practicing skills, it involves analyzing and understanding patterns from massive datasets for LLMs. They do this to make sense of human language, which allows them to generate or understand text in a helpful way. This process requires not just intelligent algorithms but also the support of substantial computing power to manage and learn from the data they’re fed.
Here’s a breakdown of the key components:
Machine Learning and Deep Learning
LLMs are built on the foundation of machine learning, specifically focusing on deep learning, a sophisticated form of machine learning utilizing neural networks with multiple layers. The term “deep” in deep learning refers to the multiple layers of neural networks. This approach enables the model to discern intricate patterns within data by fine-tuning the weights within the network during the training process.
Neural Networks
Neural networks are computational models that draw inspiration from the structure of the human brain. They are composed of interconnected nodes, also known as neurons, which are organized into three main layers:
- Input layer: This layer receives the initial data or input.
- Hidden layers: These layers process the input data through weighted connections, applying activation functions to introduce non-linearity and extract relevant features.
- Output layer: The final layer produces the ultimate result or prediction based on the processed input data.
Transformer Models
Transformer models are neural network architectures that excel at processing sequential data, like text. Introduced in the paper “Attention is All You Need,” written by Ashish Vaswani, a group from the University of Toronto, and a team at Google Brain, transformers weigh the significance of different words in a sentence, allowing the model to understand context more effectively. They can translate text and speech quickly and are used in OpenAI’s popular ChatGPT.
Tokenization
Before processing, text is broken down into smaller units called tokens (words, subwords, or characters). Tokenization converts raw text into numerical representations that the model can interpret.
Training large datasets and parameters
LLMs are trained on extensive datasets comprised of books, articles, websites, and other text sources. During training, the model adjusts its parameters (the weights and biases in the neural network) to minimize errors in predicting the next word in a sequence.
How Are LLMs Trained?
The process of training a Large Language Model (LLM) involves five crucial steps:
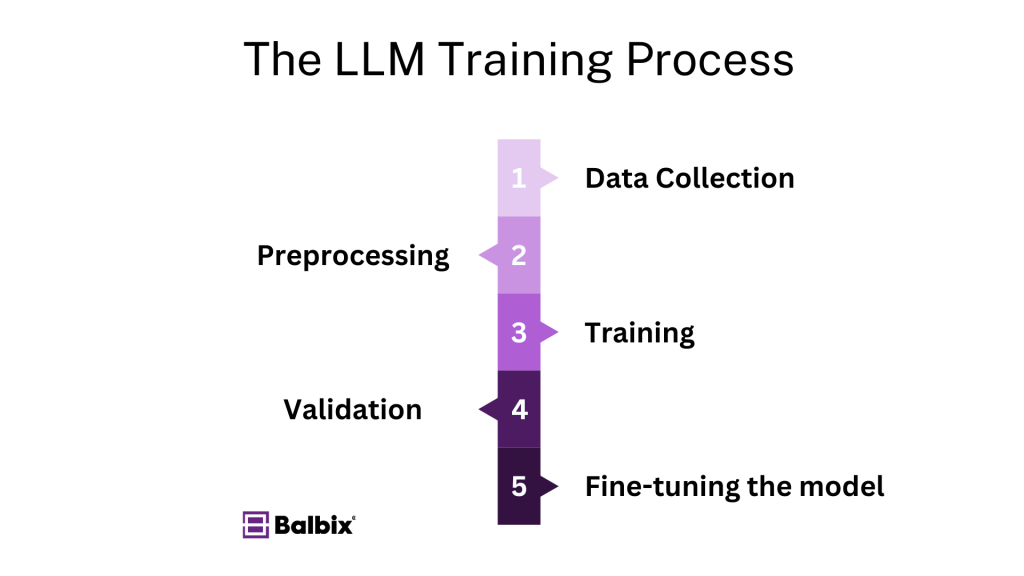
- Data collection: This initial step requires the accumulation of a substantial and diverse textual dataset to ensure the model’s exposure to a wide range of language patterns and contexts.
- Preprocessing: In this phase, the collected data undergoes thorough cleaning to remove any inconsistencies or errors. Additionally, the data is tokenized, which involves breaking it down into smaller units or tokens for further analysis.
- Training: The model is trained by feeding it with the preprocessed data. The model’s parameters are continually adjusted during this stage using optimization algorithms such as stochastic gradient descent (SGD) to enhance its performance and accuracy.
- Validation: Once the model is trained, it is validated using previously unseen data. This step evaluates the model’s performance and ensures it can effectively handle new inputs. Furthermore, validation helps identify and prevent overfitting, where the model excessively aligns with the training data, potentially leading to poor generalization of new data.
- Fine-tuning: After the initial training, the pre-trained model may undergo further adjustments to tailor for specific tasks or domains. This involves training the model on specialized datasets relevant to the targeted applications and refining its capabilities for specific use cases.
What Are LLMs Used For?
LLMs have a broad range of applications across numerous industries.
Pre-trained LLMs
Advanced AI models like GPT-4 come with pre-existing training. Without further training, they can carry out various tasks such as language translation, text summarization, content generation, and answering questions.
Deployment models
LLMs can be implemented on various cloud platforms and edge devices. They can also seamlessly incorporate into applications through APIs, providing users with various deployment options.
Retrieval-Augmented Generation (RAG)
Retrieval-augmented generation (RAG) involves combining large language models (LLMs) with external data sources to enrich the model’s outputs with current and precise information from databases or the Internet.
What Are the Benefits of LLMs?
Large Language Models (LLMs) are transforming society, promising to enhance our lives in both personal and professional aspects. By enabling machines to understand and generate human-like language, LLMs are bridging the gap between humans and computers, unlocking new possibilities across various industries.
Enhanced Natural Language Understanding
One of the most significant advantages of LLMs is how they can understand and generate text that closely mirrors human language, making human-computer interaction more natural and conversational. Users can communicate with AI systems using everyday language without requiring specialized commands or programming knowledge.
Increased Productivity
LLMs automate time-consuming tasks, allowing individuals and organizations to focus on more complex and creative endeavors. They can draft emails, generate reports, summarize lengthy documents, and even assist in writing code. For example, professionals can use LLMs to quickly create first drafts of proposals or articles, which they can refine.
Improved Accessibility and Inclusion
By opening the door to more accessible technology solutions, LLMs play a crucial role in promoting inclusivity.
They can power voice-activated assistants that help individuals with disabilities navigate digital environments more effectively; they enable real-time translation services, breaking down language barriers and allowing people from different language backgrounds to communicate seamlessly; they can provide personalized learning experiences by adjusting content to suit individual reading levels or learning styles.
Better Decision Making
Organizations can leverage LLMs to analyze large datasets to gain valuable intelligence. For example, LLMs can interpret market trends and generate forecasts in finance, helping investors make profitable choices. They also help in healthcare by analyzing medical records and research papers to help doctors diagnose conditions or recommend treatments.
Economic Growth and Job Creation
Adopting LLMs drives economic growth by creating new markets and job opportunities in AI development, data science, and related fields. Businesses integrating LLMs into their operations can gain a competitive advantage through increased efficiency and innovation.
What Are the Challenges of LLMs?
While large language models have unlocked unprecedented natural language understanding and generation capabilities, they are imperfect. If you’ve used ChatGPT, Alexa or Siri, you know they have their moments. However, the issues surrounding LLMs go far beyond chatbots.
Understanding these hurdles is essential for leveraging LLMs responsibly and effectively.
Data Privacy and Security
One key concern with LLMs is their potential impact on data privacy and security. These models are trained on massive datasets that may include sensitive or personal information. During the training process, LLMs can inadvertently memorize chunks of this data. In certain cases, they might divulge confidential information when generating text, which may cause data leakage.
For example, suppose an LLM is trained on unfiltered user data from social media or private communications. In that case, it might generate outputs that include personally identifiable information (PII) or proprietary corporate data. This scenario raises serious privacy concerns, especially under regulations like the General Data Protection Regulation (GDPR), the California Consumer Privacy Act (CCPA), or the Digital Operations Resilience Act (DORA), which mandates strict controls over personal data handling.
Organizations must implement robust data governance policies when using LLMs. This includes anonymizing datasets, obtaining necessary consent, and ensuring compliance with all relevant regulations.
Ethical Considerations
LLMs learn from the data they are fed, which means they can inadvertently absorb and perpetuate the biases present in those datasets. If the training data contains discriminatory or offensive content, the model may generate outputs that reflect these biases.
It is also important to note that LLMs have not reached a true understanding or consciousness. They generate text based on data patterns, meaning they can produce plausible but incorrect or misleading information. The consequences can be dire in contexts where accuracy is non-negotiable —such as medical advice, legal information, or news reporting.
Technical Limitations
From a purely technological standpoint, LLMs need significant computational resources and scalability. Training state-of-the-art models requires massive amounts of data and processing power. It can be time-consuming and expensive for companies and requires specialized hardware like high-end GPUs or TPUs.
LLMs in Cybersecurity
Security threats are becoming more sophisticated and pervasive. Large Language Models can boost organizations’ cybersecurity efforts by enhancing threat detection, automating responses, and providing deeper insights into vulnerabilities.
Enhancing Threat Detection and Analysis
LLMs can process and analyze vast amounts of textual data, such as system logs, network traffic data, and user communications. They can predict security weaknesses by analyzing configuration files, access logs, and software inventories.
For example, LLMs can be trained to recognize tell-tale linguistic signs of a phishing email or social engineering attempt. They can analyze email content to flag suspicious messages before they reach users, drastically reducing the risk of successful phishing attacks.
LLMs can also help interpret code or scripts to identify malicious intent by analyzing their code patterns and command structures.
Automating Incident Response and Management
Every second is valuable in the event of a security breach. LLMs can automate the initial incident response by quickly analyzing the scope and impact of the breach. They can generate detailed reports, summarize findings, and suggest remediation steps based on best practices.
For example, an LLM-powered system could parse through security alerts, correlate related events, and provide a concise summary to the security team so they can focus on strategic decision-making rather than sorting through endless logs.
Vulnerability Assessment and Predictive Analysis
LLMs can contribute to proactive cybersecurity measures by identifying vulnerabilities within systems and networks. They can predict security weaknesses by analyzing configuration files, access logs, and software inventories.
LLMs can also simulate attack scenarios, helping organizations understand how an attacker might exploit certain vulnerabilities.
Contextualizing LLMs with Balbix’s BIX
Balbix’s BIX platform is a great use case for LLMs in cybersecurity. BIX leverages AI and machine learning to provide comprehensive visibility into an organization’s security posture. Balbix continuously analyzes data from various sources, helping identify risks and prioritize actions.
BIX was designed to use advanced algorithms to assess the likelihood of breaches across different assets and attack vectors. It provides actionable intelligence by translating complex security data into understandable metrics and recommendations. With BIX, organizations can make informed decisions and allocate resources effectively to mitigate risks.
Frequently Asked Questions
- What are Transformer models, and why are they important for LLMs?
-
Transformer models are a type of neural network architecture that excels at processing sequential data, like text, by weighing the significance of different words in a sentence. This allows the model to understand context more effectively, making them crucial for the performance of LLMs, particularly in tasks like text translation and speech recognition.
- What are some applications of LLMs?
-
Large Language Models have a wide range of applications, including but not limited to, improving human-computer interaction through natural language processing, content creation, language translation, and enhancing cybersecurity measures by understanding and predicting potential threats in communication.
- How can LLMs and AI automate Security Awareness Training?
-
Human error remains one of the largest vulnerabilities in cybersecurity. LLMs can be used to create customized, interactive security awareness training for employees. By analyzing employees’ interactions and responses, LLMs can adapt the training content in real-time to focus on areas where each employee needs the most improvement, thereby enhancing the overall effectiveness of cybersecurity training programs.


