

September 21, 2023
Why Your DIY Security Data Lake Might Just Sink?

Anuj Magazine
12 min read | Security Posture
September 21, 2023
Sarah, the battle-hardened CISO, oversees a formidable array of cybersecurity tools. Her organization has invested in next-gen IDS/IPS, state-of-the-art firewalls, and MFA protocols. They’ve even ventured into EDR, Zero Trust architecture, and vulnerability management tools to detect and remediate vulnerabilities proactively. Recently, her team rolled out an asset inventory tool to keep tabs on the growing number of devices and applications in the network. Each tool operates in its silo, generating its own set of alerts and reports, adding to the analytical workload rather than lightening it.
In this sea of complexity, Sarah feels like she’s drowning. Each security tool in her arsenal generates its cascade of alerts, with no easy way to prioritize or correlate them. While Security Information and Event Management (SIEM) systems often use data lakes to centralize real-time monitoring and alerting, Sarah faces a different, yet interrelated, challenge. Her conundrum concerns more than just real-time responses but also understanding and quantifying the broader risks associated with the current cybersecurity landscape.
In the context of her security challenges, Sarah discovers that even her asset inventory tool, designed to provide a comprehensive attack surface picture, falls short of tying into the overarching cybersecurity landscape. Despite the variety of tools at her disposal, she notices glaring coverage gaps that none of her solutions adequately address.This barrage of information creates an ‘analysis paralysis,’ where crucial alerts can slip through the cracks, camouflaged by many false positives and low-priority issues. Her multiple dashboards feel like a maze with no exit, each one demanding specialized expertise and none offering a bird’s-eye view of the overall security posture. When it comes to her quarterly board meetings, the situation grows even grimmer. Sarah has an ocean of data but lacks a navigable map to sail through it. Board members ask pointed questions about cyber risk, but the fragmented data prevents her from painting a unified and quantifiable picture. The tools that should empower her create a web of confusion, leaving Sarah and her team in perpetual anxiety and uncertainty.
Sarah’s plight is not isolated; it’s more a pervasive issue. When it comes to cybersecurity, the challenges Sarah faces in navigating the maze of fragmented data and disparate tools echo the frustrations that we have often heard in our discussions with Fortune 1000 prospects.
A security leader from one of Canada’s leading Integrated Health Services companies echoed this sentiment:
“Although our dashboard is 80% automated, sourcing data through APIs from third-party assessment tools, vulnerability management systems, phishing awareness programs, and our SOC, the remaining 20% manual effort unveils a significant issue. Even with all these categories of tools, we’re not equipped to convey what the board most needs to understand. I want to be able to tell them, ‘Our existing risks could result in a $5 million loss by the end of the year.’ Without that level of quantified risk assessment, our array of tools and data falls short of grabbing the board’s attention on the critical issues at hand.”
The approach they followed to solve the problem of siloed data from tools was the creation of a DIY data lake. Such repositories are prevalent among large organizations, serving as centralized hubs for aggregating and analyzing a wide array of raw security data from various tools and platforms. The ultimate aim is to provide a cohesive snapshot of an organization’s cyber risk landscape for facilitating more informed decision-making. However, given the challenges many of our customers and prospects have encountered, it raises serious questions about the actual effectiveness of DIY Security Data Lakes. What’s behind this discrepancy?
Our engagement with Fortune 1000 companies reveals that about 25% have invested in some form of security data lake, with annual expenditures often exceeding $5 million. Maintaining a data lake requires significant investments – ever-growing scale, increasing and diverse data sources, periodically changing data schemas and APIs from each such tool, evolving technologies – all require a considerable engineering effort and opex that security teams, already stifled for resources, cannot continually provide and budget for. And even when they try, this significant financial commitment hasn’t translated into satisfaction; fewer than 10% of executives believe these initiatives meet their objectives. Consequently, most are left struggling to quantify cyber risk effectively, raising serious doubts about the true value of these costly data lake endeavors.
The DIY security data lake concept may sound good on paper, but it’s fraught with challenges that can impede its utility, even in well-funded organizations. Here are some of the critical issues:
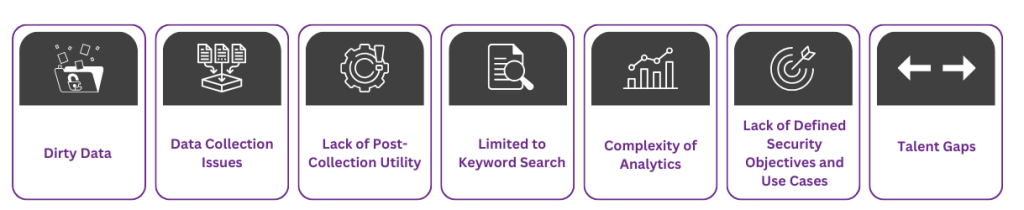
The shortcomings of traditional DIY security data lakes invite a pressing question: Is there a better way to aggregate and make sense of the sprawling cybersecurity landscape? Organizations desperately need a more holistic framework that serves as a unified repository for data across various security, IT, and business tools and scales efficiently while managing costs. The goal should be to provide real-time, continuous visibility into cyber risk, with actionable, inspectable insights that offer clear guidance on aspects like which software needs patching and how to choose among multiple patch options.
Imagine trying to conduct a symphony orchestra without a musical score, where each section of musicians plays from different compositions. In this scenario, extensive data models and connector frameworks act like the musical score, coordinating the instruments (data sources!) to produce a harmonious sound. They provide the structure for data ingestion, correlation, deduplication, and aggregation at individual asset levels, laying the groundwork for effective cybersecurity. Without this coordinating score, each section may play its tune well, but collectively, they produce a cacophony, making it nearly impossible to understand the intended composition. Therefore, when assessing the limitations of DIY data lakes, the importance of well-designed data models and frameworks that can integrate various data sources should not be overlooked.
In conclusion, while DIY Security Data Lakes offer the promise of centralizing and analyzing vast amounts of security data, they often fall short due to issues like data quality, complexity, and lack of focus. Organizations truly need a more cohesive and scalable solution that offers actionable, inspectable insights for managing cyber risk effectively. Stay tuned: in the next blog, we will discover how Balbix’s rapid integration framework works and delivers strategic value.If you’d like to learn more about how Balbix can eliminate the headaches associated with deploying and managing a data lake for risk and cybersecurity posture management, please sign up for a 30-minute demo.