October 13, 2025
When “Good Enough” Hallucination Rates Aren’t Good Enough (and Why the Agentic AI Hype Misses the Point)

Gaurav Banga
19 min read | Artificial Intelligence, CTEM, Security Posture
October 13, 2025
Vendors will tell you their latest models “hallucinate less. That’s true in a narrow, benchmark sense—but even the best numbers are far from zero, and they vary widely by task and context.
OpenAI’s 2025 paper, Why Language Models Hallucinate, captures the issue precisely:
“Hallucinations are not a mysterious artifact of neural networks.
They are a predictable outcome of how we train and evaluate language models:
we reward guessing over admitting ignorance.”
— Kalai, Nachum, Vempala, Zhang (OpenAI, 2025)
When forced to answer every question, even GPT-4-class systems produced 20–30% factual errors. When allowed to abstain, their accuracy improved substantially, but only by refusing to answer more than half the questions. Or, as the paper explains, “Current benchmarks measure accuracy conditional on answering, not on the decision to answer.”
That insight matters deeply in exposure management, where factual precision—not fluency—determines operational safety.
Hallucination isn’t a solved problem, it’s just better measured. Recent public data makes the picture clear.
| Model | Benchmark / Source | Hallucination Rate |
| GPT-4o | Vectara FaithJudge (Nov 2024) | ≈ 15.8% |
| Claude 3.7 Sonnet | Vectara FaithJudge (Feb 2025) | ≈ 16.0% |
| Gemini 2.5 Flash | Vectara FaithJudge (Mar 2025) | ≈ 6.3% |
Note that Google’s Gemini, at a great-looking 6%, was evaluated on general question-answering, not enterprise security decision pipelines. Less hallucination under lab conditions doesn’t equate to “trustworthy” in production.
OpenAI now claims GPT-5 “hallucinates significantly less, especially in reasoning,” and Anthropic’s Claude 4 system card details stronger citation and safety controls. But both companies still acknowledge residual hallucinations.
Progress is real; elimination is not.
In cybersecurity, confident errors are worse than ignorance. In exposure management, systems depend on structured truth. A hallucinated “fact” isn’t just noise, it’s a corrupted decision input. At a typical hallucination rate of 5–10%, these systems introduce errors that scale nonlinearly with business risk. A single incorrect field in an asset record can misprioritize dozens of vulnerabilities. A single wrong patch-state assumption can misstate compliance by thousands of endpoints. Every hallucination carries a cost multiplier in time, rework, and residual exposure.
Let’s review a few examples:
| # | Failure Mode / Example | What Happens | Operational or Financial Impact |
|---|---|---|---|
| 1 | Risk Prioritization Drift | The AI “fills in” missing metadata, assuming an internal asset is internet-facing. | Risk scores inflate; remediation teams waste cycles patching low-risk systems while true internet-exposed assets remain vulnerable. |
| 2 | Patch Status Misclassification | The model misinterprets a Windows KB or assumes “installed” = “active.” | Tickets close prematurely on 5% of systems. The illusion of compliance masks live exploit paths. |
| 3 | Vulnerability Mapping Errors | During enrichment, AI links CVEs to the wrong software components. | Analysts chase false positives, inflating workload by 20–30% and delaying high-severity remediation. |
| 4 | Software Inventory Mismatch | LLM normalization merges OpenSSL 1.0.2u with 1.1.1n. |
Cryptographic libraries appear patched. Unseen vulnerabilities linger—potential breach vectors worth millions in potential loss. |
| 5 | Control Attribution Hallucination | AI assumes segmentation or EDR controls are inherited via policy groups. | Risk scoring underestimates reachable attack surfaces; incident containment models fail in live events. |
| 6 | Asset Role Mislabeling | AI reclassifies a production database as a test instance based on naming similarity. | Backups, monitoring, and least-privilege policies misapply; recovery time objectives are missed after an outage. |
| 7 | Data Localization and Compliance Drift | Hallucinated region or ownership fields cause regulatory misreporting. | GDPR, HIPAA, or PCI attestations fail audit review; fines and remediation costs escalate. |
| 8 | Threat Intelligence Misattribution | AI correlates unrelated IOCs to a trending CVE. | SOC analysts chase non-existent campaigns, burning hours of analyst time and incident response resources. |
Even a 6 percent hallucination rate, considered excellent by benchmark standards, translates into serious operational risk. In a vulnerability catalog of 10,000 items, that’s 600 corrupted records. In an enterprise asset base of 100,000 nodes, 6,000 inaccurate decisions influencing budgets, SLAs, and control posture.
The downstream impact is broad and measurable:
A “small” hallucination rate quickly becomes a large-scale enterprise integrity problem—an error that propagates across systems, decisions, and trust. Security teams don’t fear silence from an AI. They fear confident nonsense!
In an earlier Balbix blog, I described how human cognition operates in two complementary modes, as articulated by Daniel Kahneman in Thinking, Fast and Slow.
Most large language models live squarely in System 1. They are fluent, confident, and associative—but not self-aware. They generate plausible outputs without verifying them. To make AI reliable in enterprise workflows, we need to surround that intuitive System 1 capability with a System 2 framework that checks facts, validates logic, and enforces consistency.
Structured AI is that System 2 layer.
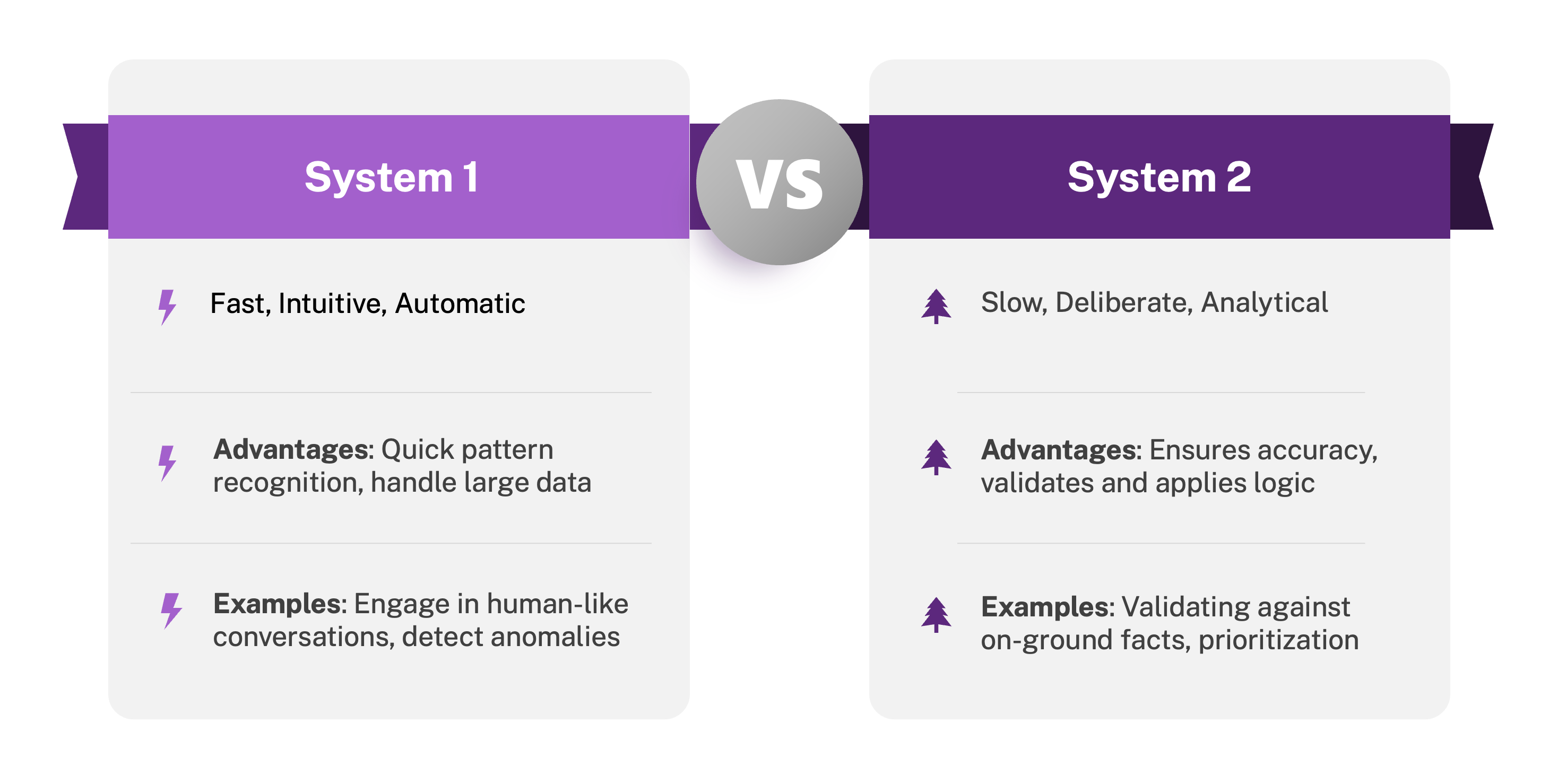
It continuously evaluates new signals, updates the enterprise risk graph, and analyzes exposure in a consistent, repeatable, and explainable way—efficiently enough for real-time operations, but rigorous enough to be trusted.
In the enterprise cybersecurity world, information never arrives cleanly. Asset inventories are incomplete, scan results overlap, vulnerability feeds conflict, and business context changes faster than it can be documented. Making sense of this requires layered reasoning: a system capable of ingesting raw and partially processed data, reconciling contradictions, filling gaps responsibly, and then producing decisions that are both explainable and repeatable.
That’s why Balbix was designed as a multi-layered Structured AI stack, not a single end-to-end model.
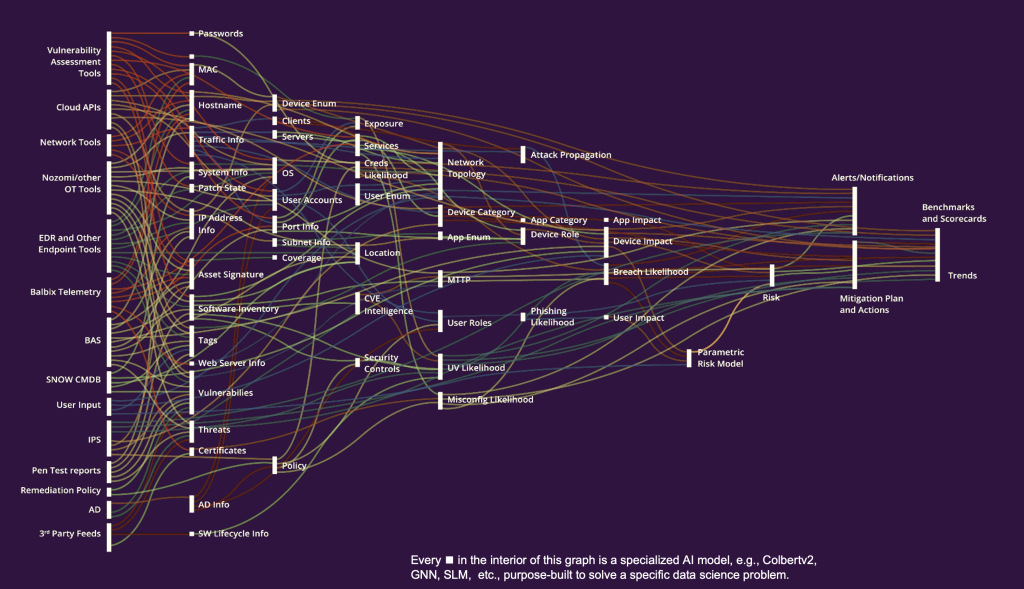
Each layer specializes in a different stage of reasoning: one cleans and normalizes inputs, another fetches corroborating evidence, another ranks risks, and others enforce consistency, forecast drift, and explain every decision.
Together, these layers form a disciplined reasoning pipeline that continuously integrates imperfect, conflicting, and dynamic signals into a coherent, trustworthy understanding of enterprise risk.
| Layer | Example Algorithms | Primary Function |
|---|---|---|
| Understanding | Sentence-BERT, E5-v2, Custom NER | Normalize noisy inputs—asset names, software versions, tags—into canonical entities. |
| Retrieval | TF-IDF, SPLADE, BM25 Hybrid | Fetch authoritative telemetry from scanners, SBOMs, and configurations—never guess. |
| Judgment & Ranking | LambdaMART, MonoT5, CoLBERT v2 | Prioritize exposures using validated evidence and business impact. |
| Classification | XGBoost, SAINT, TabTransformer | Maintain schema integrity across asset and zone types for consistent comparison. |
| Constraint Enforcement | Mixed-Integer Programs | Guarantee logical consistency (e.g., patch date < discovery; control state = verified). |
| Propagation & Forecasting | MPNN, Graphormer, N-BEATSx | Update the risk graph—model how vulnerabilities spread or decay over time. |
| Interpretability | SHAP, Integrated Gradients | Explain why each score or decision occurs—feature by feature, control by control. |
This architecture turns AI intuition into governed reasoning. Every new telemetry signal, an asset scan, vulnerability scan, threat feed update, control change, or business context update, flows through a structured pipeline that:
When models disagree, this system abstains or escalates, it never fabricates. This enforces the principle we’ve championed since we started building Balbix: retrieval before reasoning, validation before ranking, abstention before assumption.
Structured AI provides the deliberate, analytical System 2 discipline that intuitive GenAI lacks—creating decisions that are consistent, evidence-based, and repeatable at enterprise scale.
At Balbix, we’re not competing with Generative AI: we’re harnessing it for what it does best.
Human beings think, explain, and make decisions through natural language, especially in business contexts. In our view, GenAI’s strength is exactly that: understanding intent, interpreting nuance, and communicating fluently.
In Balbix, the GenAI subsystem (called BIX) acts as the conversational intelligence layer. It is the bridge between human curiosity and the structured reasoning of our AI engine. It enables anyone, from a vulnerability analyst to a CISO, to ask questions naturally, such as: “Which business units are carrying the highest unpatched exposure?” and receive answers that are both precisely correct and immediately understandable.
When a user asks BIX a question, GenAI performs the first critical task: intent understanding. It parses language, clarifies context, and maps the question to the schema and vocabulary of the Structured AI backend.
If the mapping can’t be made with high confidence, BIX doesn’t guess. Instead, the GenAI system iterates, asking clarifying questions or reformulating internally, until the system reaches confident understanding of what the user truly wants.
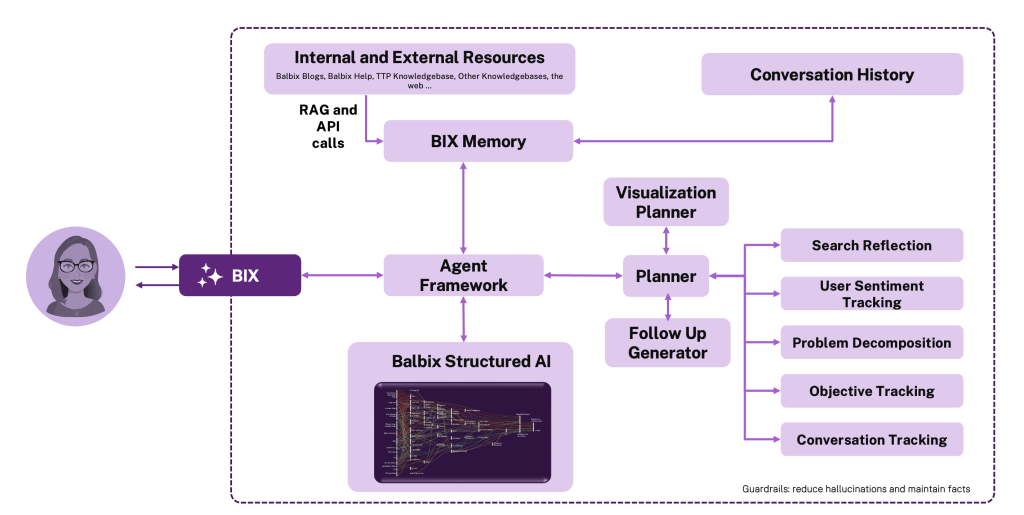
Once intent is resolved, BIX invokes the Structured AI layer, which retrieves and analyzes authoritative telemetry:
asset data, vulnerabilities, control states, and business context. This Structured AI generates a structured, deterministic answer, which is evidence-based, consistent, and linked to artifacts .
Finally, GenAI transforms that structured response back into clear, human language. It restates the system’s understanding of the question and delivers the answer with System 1 fluency grounded in System 2 precision. If Structured AI does not have enough evidence to answer confidently, GenAI is instructed to says so, explicitly and transparently.
This separation of roles is deliberate.
GenAI delivers System 1 fluency—the ability to understand and communicate naturally—while Structured AI provides System 2 rigor—the reasoning, validation, and consistency enterprises depend on. Together, they allow humans to interact with complex cybersecurity data as effortlessly as conversation, without sacrificing accuracy, safety, or accountability.
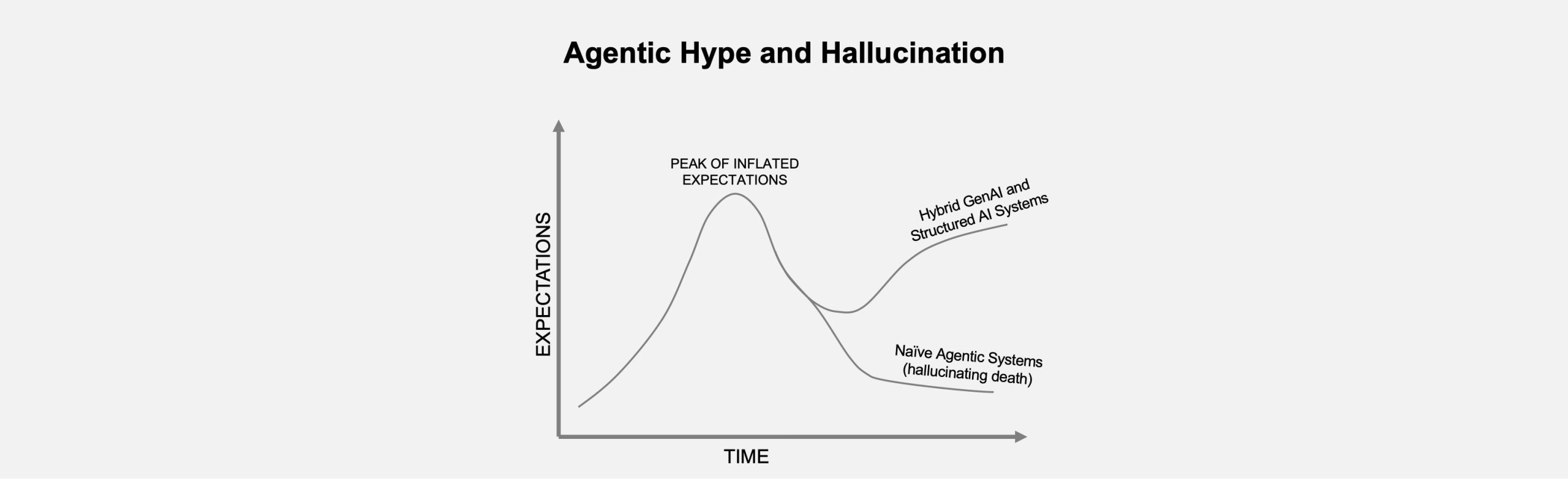
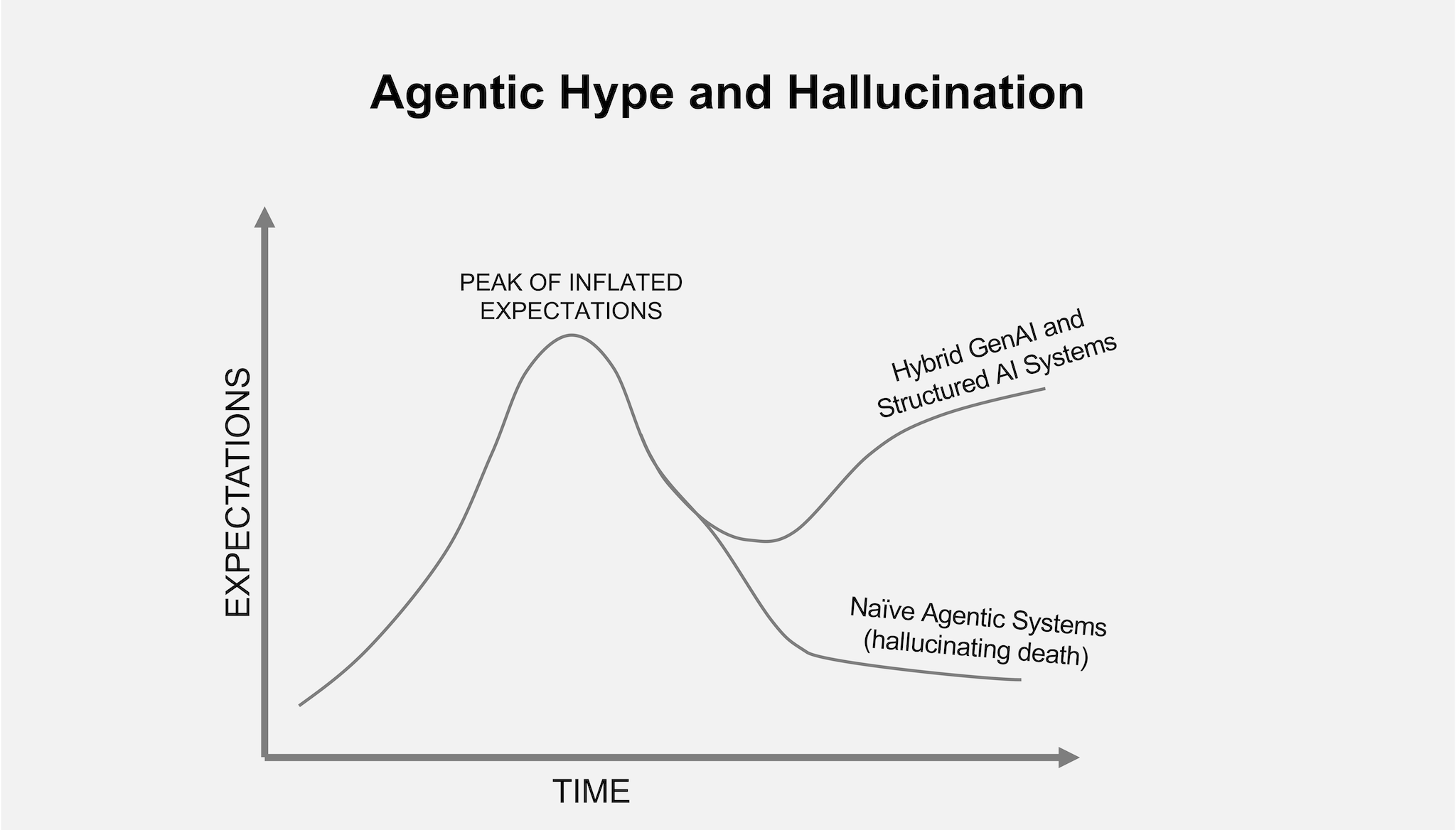
The new wave of AI enthusiasm centers on “agentic” systems, models that can plan, reason, and act autonomously.
In cybersecurity, the idea is appealing in theory and perilous in practice. The notion of an AI system that could not only prioritize vulnerabilities but also create change requests, deploy patches, or update configurations sounds transformative. Unfortunately, most Agentic AI cybersecurity offerings today are based on an unfinished architecture while pretending to be an operational system.
| Agentic Weakness | Why It Fails in Production |
|---|---|
| Incomplete Context | Real-world security data are always partial; plans built on gaps are coherent but wrong. |
| Overconfidence Bias | Reward functions and benchmarks still prioritize completion over correctness. |
| Unweighted Citations | Source attribution without provenance weighting reinforces false confidence. |
| Incentive Mismatch | Demos reward spectacle, not safety; validation and rollback logic remain unfunded. |
Naively built agentic systems in cybersecurity don’t just make things up, they make them up unpredictably, executing confidently on unverified premises.
Without epistemic hygiene, evidence weighting, consistency checks, and abstention gates, autonomy quickly becomes automation without accountability. To deliver the true promise of Agentic AI, you need a system like Balbix, one that fuses System 1 fluency with System 2 structure, bringing intuition and action under governance.
One common attempt to improve reliability has been the use of GenAI ensembles, multiple large models working together, cross-checking one another’s answers. It’s a promising idea, but still a fragile foundation for enterprise-grade autonomy.
Ensembles can reduce random error: when models disagree, it signals uncertainty; when they agree independently, confidence appears to rise. They work well for summarization, content synthesis, or exploratory analysis, places where approximation is acceptable. But in cybersecurity, where precision matters, ensemble consensus is often false confidence.
If every GenAI model shares similar training gaps, they will converge on the same wrong answer. And because ensemble frameworks still operate entirely within System 1 reasoning—fast, intuitive, associative—they lack the deliberate verification that distinguishes correct reasoning from agreement.
| Ensemble Challenge | Why It Matters | Structured AI Mitigation |
|---|---|---|
| Shared Bias | Models trained on overlapping data repeat the same misconceptions. | Structured AI cross-verifies against authoritative telemetry. |
| Consensus Illusion | Agreement ≠ correctness; multiple models can be wrong together. | Evidence-weighted retrieval and post-generation validation. |
| Operational Cost | Multi-model orchestration increases latency and expense. | Deterministic filters limit GenAI usage to ambiguous cases. |
| Explainability Gap | Voting results offer no rationale for the chosen output. | Structured AI provides interpretable scoring and auditability. |
| Safety Limitations | Ensembles lack policy awareness or action validation. | Plan-first validation and guardrails ensure safe execution. |
In summary, GenAI ensembles can reduce variance, but they can’t eliminate systemic error. They are multiple instances of System 1 collaborating, intuition multiplied, not reason applied. To reach dependable autonomy, Agentic AI needs a governing System 2 layer: structured logic, validation, provenance tracking, and rollback safety.
Balbix’s architecture provides the critical ingredients that real Agentic AI requires:
 This is how agentic behavior becomes trustworthy, when action is coupled with verification, and autonomy is bounded by evidence. Balbix delivers the missing System 2 layer that makes Agentic AI safe, accountable, and enterprise-ready.
This is how agentic behavior becomes trustworthy, when action is coupled with verification, and autonomy is bounded by evidence. Balbix delivers the missing System 2 layer that makes Agentic AI safe, accountable, and enterprise-ready.
True intelligence isn’t just the ability to act, it’s the ability to act correctly, transparently, and repeatably.
Much of the current AI safety conversation focuses on malicious misuse: prompt injection, data exfiltration, IP protection. That work is important, and long overdue. I have written about this topic as well, in the context of BIX.
But the bigger, quieter risk is everyday correctness—AI making small, confident errors inside the workflows that power our businesses.
AI safety isn’t only about preventing catastrophic behavior; it’s about ensuring reliability at scale.
Would you tolerate a 5% error rate in your payroll system? In your expense forecasts to your board? In your customer support responses to troubleshooting questions?
Yet we routinely accept similar or higher error rates in AI tools handling customer interactions, analytics, and even risk prioritization. The problem isn’t malevolence, it is misplaced tolerance.
Until we bring AI correctness to the same standard we demand of other business systems, the industry will continue mistaking eloquence for accuracy.
GenAI gives fluency. Structure gives truth.
Hallucination control doesn’t come from bigger models, it comes from correct system architecture. The Balbix Brain integrates retrieval, logic, and interpretability into a system that is auditable, explainable, and deterministic.
In exposure management, confidence without correctness isn’t intelligence—it’s liability. The winners in this new era won’t be those who automate fastest, but those who constrain smartest.